 1,993 Views
1,993 Viewsโอซีอาร์เป็นคำย่อของภาษาอังกฤษ คือ "Optical Character Recognition : OCR" แปลเป็นภาษาไทยได้ว่า "การรู้จำอักขระด้วยแสง" ซึ่งเป็นงานประยุกต์งานหนึ่งของสาขาวิทยาการคอมพิวเตอร์ที่ได้รับความสนใจและพัฒนามานานกว่า ๗๐ ปีแล้ว โอซีอาร์เป็นการรู้จำรูปแบบตัวอักษรซึ่งเป็นงานวิจัยในสาขาการรู้จำรูปแบบ (Pattern Recognition) เป็นเทคโนโลยีที่ส่งผลให้ระบบคอมพิวเตอร์สามารถระบุรูปแบบได้อย่างถูกต้อง เช่น สามารถบอกได้ว่าภาพนั้นคือภาพอะไร ตัวอักษรนั้นคือตัวอักษรอะไร หรือเสียงนั้นคือเสียงของคำสั่งอะไร เป็นต้น
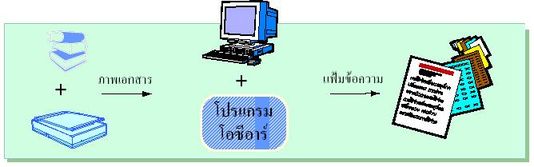
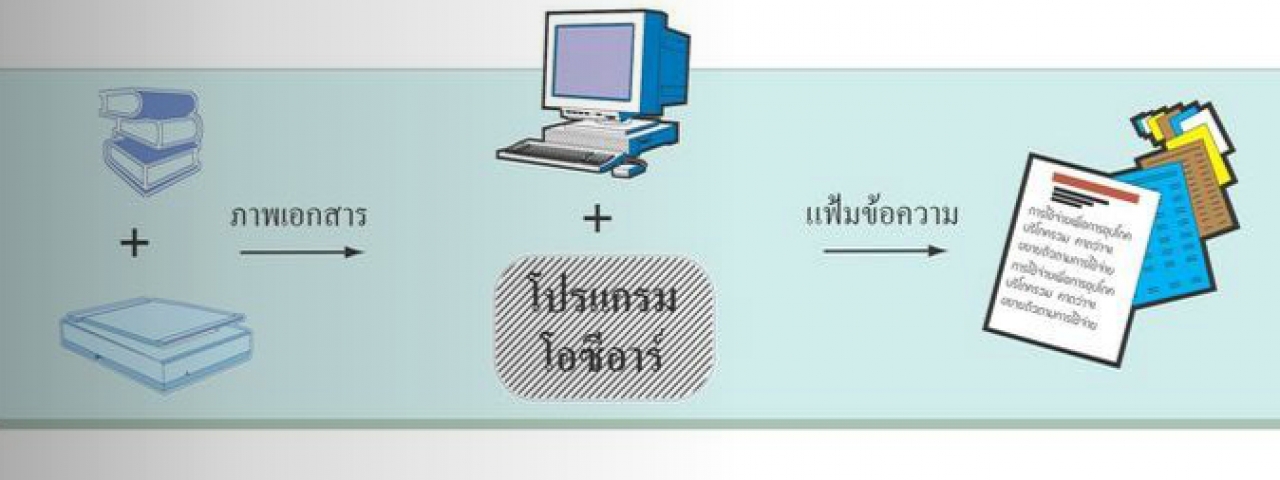
นักวิจัยเป็นจำนวนมากมีความสนใจงานโอซีอาร์เพราะเป็นงานที่เกี่ยวข้องกับเอกสารซึ่งมีปริมาณมากมายมหาศาล การเก็บข้อมูลเหล่านี้ให้เป็นแฟ้มข้อความ (Text File) ไว้ในระบบคอมพิวเตอร์นั้นต้องใช้บุคลากรในการจัดพิมพ์เอกสารนั้น ๆ โดยใช้โปรแกรมพิมพ์และประมวลผลเอกสาร (Word Processing Program) ถึงแม้ว่าโปรแกรมประเภทนี้จะมีความสามารถและเป็นเครื่องมือที่ดี แต่ก็ต้องใช้บุคลากรในการพิมพ์งานซึ่งใช้เวลามากพอสมควรและยังเป็นงานที่จำเจสำหรับบุคลากรอีกด้วย ถ้าโอซีอาร์ประสบความสำเร็จงานพิมพ์เอกสารต่าง ๆ เพื่อเก็บเป็นแฟ้มข้อความก็จะกลายเป็นหน้าที่ของระบบคอมพิวเตอร์แทน โดยทั่วไปแล้วเวลาในการประมวลผลของโอซีอาร์จะเร็วกว่าการพิมพ์ด้วยมนุษย์โดยเฉลี่ยประมาณ ๕ เท่าและในบางระบบงานที่ได้จากโอซีอาร์จะมีความถูกต้องมากกว่างานที่ได้จากการพิมพ์ของมนุษย์อีกด้วยจึงทำให้งานวิจัยด้านโอซีอาร์ได้รับความนิยมเป็นอย่างมาก
ประเทศไทยเริ่มจะมีงานวิจัยเรื่องโอซีอาร์สำหรับใช้งานกับเอกสารภาษาไทยในระยะเวลาประมาณ ๑๐ ปีที่ผ่านมานี้เท่านั้นและเพื่อความสะดวกในการกล่าวถึงงานวิจัยโอซีอาร์สำหรับภาษาไทย จึงเป็นที่นิยมโดยทั่วไปที่จะเรียกงานวิจัยในสาขานี้ว่า "ไทยโอซีอาร์" ซึ่งมีการทำวิจัยทั้งในหน่วยงานภาครัฐและภาคเอกชน ตัวอย่างการทำวิจัยในสาขานี้ของทางภาครัฐ เช่น สถาบันเทคโนโลยีพระจอมเกล้าเจ้าคุณทหารลาดกระบังโดย ดร. ชม กิ้มปาน สถาบันบัณฑิตพัฒนบริหารศาสตร์ โดย ดร. พิพัฒน์ หิรัญวนิชกร จุฬาลงกรณ์มหาวิทยาลัย โดย ดร. ชิดชนก เหลือสินทรัพย์ และ ดร. สมชาย จิตตะพันธ์กุล ศูนย์เทคโนโลยีอิเล็กทรอนิกส์และคอมพิวเตอร์แห่งชาติโดย ดร. ทวีศักดิ์ กออนันตกูล และ ดร. จุฬารัตน์ ตันประเสริฐ เป็นต้น ส่วนทางภาคเอกชน ได้แก่ บริษัทเอเทรียม เทคโนโลยีจำกัดและบริษัทเอ็นเอสทีอิเลคทรอนิคพับลิชชิ่ง จำกัด
ซอฟต์แวร์ไทยโอซีอาร์เริ่มออกสู่ตลาดในปี พ.ศ. ๒๕๓๙ จนถึงปี พ.ศ. ๒๕๔๑ ในท้องตลาดมีซอฟต์แวร์ไทยโอซีอาร์อยู่ ๓ ซอฟต์แวร์ด้วยกัน ได้แก่ ซอฟต์แวร์ไทยโอซีอาร์ของบริษัทเอเทรียม เทคโนโลยีจำกัด ซอฟต์แวร์อ่านไทยโดยความร่วมมือระหว่างศูนย์เทคโนโลยีอิเล็กทรอนิกส์และคอมพิวเตอร์แห่งชาติกับบริษัทไทยซอฟท์จำกัดและซอฟต์แวร์ทีเร็ค (T - rec) โดยบริษัทเอ็นเอสที อิเลคทรอนิคพับลิชชิ่งจำกัด ความสามารถในการรู้จำของทั้ง ๓ ซอฟต์แวร์มีความแตกต่างกันไปตามลักษณะของฟอนต์ตัวอักษรไทยหรือลักษณะของเอกสารซึ่งในปัจจุบันนี้ถือว่าความสามารถในการรู้จำของโอซีอาร์อยู่ในระดับพอใช้งานได้แต่ยังต้องการการพัฒนาปรับปรุงเพิ่มประสิทธิภาพต่อไปอีกในอนาคต